인덱스는 쿼리에서 반환할 행을 찾는 기능을 외에, 데이터를 정렬하는 기능을 제공하기도 합니다. 인덱스를 통해 별도의 정렬 연산 없이도 ORDER BY가 동작한 것처럼 쿼리 결과를 만들 수 있습니다. 현재 PostgreSQL에서 지원하는 인덱스 타입 중 B-Tree만 정렬된 출력을 생성할 수 있으며, 다른 인덱스 타입은 구현 의존적인 순서로 반환합니다. (*역자주: 쉽게 말하면 B-Tree 인덱스 이외에는 행의 순서가 제멋대로 출력된다는 뜻입니다.)
플래너는 ORDER BY가 들어간 쿼리의 실행 계획을 세울 때 두 가지 옵션을 고려합니다.
한가지는 ORDER BY에 명시된 정렬 조건과 일치하는 인덱스를 스캔하는 것이고
다른 하나는 테이블을 순서대로 스캔하고 따로 정렬 연산을 하는 것입니다.
테이블의 많은 부분을 스캔해야 하는 쿼리의 경우, 두 번째 방법이 빠를 수 있습니다. 순서대로 스캔하는 것이 인덱스를 사용하는 것보다 더 적은 디스크 I/O를 발생시키기 때문입니다. 인덱스는 몇 개의 행만 가져와야 할 때 더 유용합니다. ORDER BY와 LIMIT를 함께 사용하는 특수한 경우에는 두 번째 방법이 더 효율적입니다. 첫 번째 방법은 상위 n개의 행을 찾기 위해 전체 데이터를 정렬해야 하지만, ORDER BY 조건과 매칭되는 인덱스를 사용하면 상위 n 행을 바로 뽑아낼 수 있기 때문입니다.
기본적으로 B-Tree 인덱스는 항목을 오름차순으로 저장하며 null을 마지막에 둡니다. 즉, x 열에 있는 인덱스를 정방향으로 스캔하면 ORDER BY x(더 자세히 말하면 ORDER BY x ASC NULLS LAST)를 만족하는 출력이 생성됩니다. 인덱스를 역방향으로 스캔하여 ORDER BY x DESC를 만족하는 출력을 생성할 수도 있습니다(더 상세하게는 ORDER BY x DESC NULLS FIRST, NULLS FIRST가 ORDER BY DESC의 기본값입니다).
아래 예시처럼, 인덱스를 만들 때 ASC, DESC, NULLS FIRST 및/또는 NULLS LAST 옵션을 포함하여 B-Tree 인덱스의 순서를 조정할 수도 있습니다.
NULLS FIRST 옵션과 함께 오름차순으로 저장된 인덱스는 스캔하는 방향에 따라 ORDER BY x ASC NULLS FIRST 또는 ORDER BY x DESC NULLS LAST를 만족할 수도 있습니다.
두 가지 옵션과 역방향 스캔 가능성을 함께 사용하면 ORDER BY의 모든 변형을 포괄할 수 있는데 왜 네 가지 옵션을 모두 제공해야 하는지 궁금할 수 있습니다. 이 방식이 멀티 컬럼 인덱스에서는 유용할 수 있습니다. (x, y)에 대한 두 개의 열 인덱스를 예로 들어보면, 앞으로 스캔하는 경우 ORDER BY x, y를 충족할 수 있고 뒤로 스캔하는 경우 ORDER BY x DESC, y DESC를 충족할 수 있습니다. 그러나 애플리케이션에서 ORDER BY x ASC, y DESC를 자주 사용해야 할 수도 있습니다. 일반 인덱스에서는 이러한 순서를 얻을 수 있는 방법이 없지만, 인덱스가 (x ASC, y DESC) 또는 (x DESC, y ASC)로 정의되어 있으면 가능합니다.
물론 기본 정렬 순서가 아닌 인덱스는 상당히 특수한 기능이지만 특정 쿼리에 대해 엄청난 속도 향상을 가져올 수 있습니다. 이러한 인덱스를 유지할 가치가 있는지 여부는 특별한 정렬 순서가 필요한 쿼리를 얼마나 자주 사용하는지에 달려있습니다.
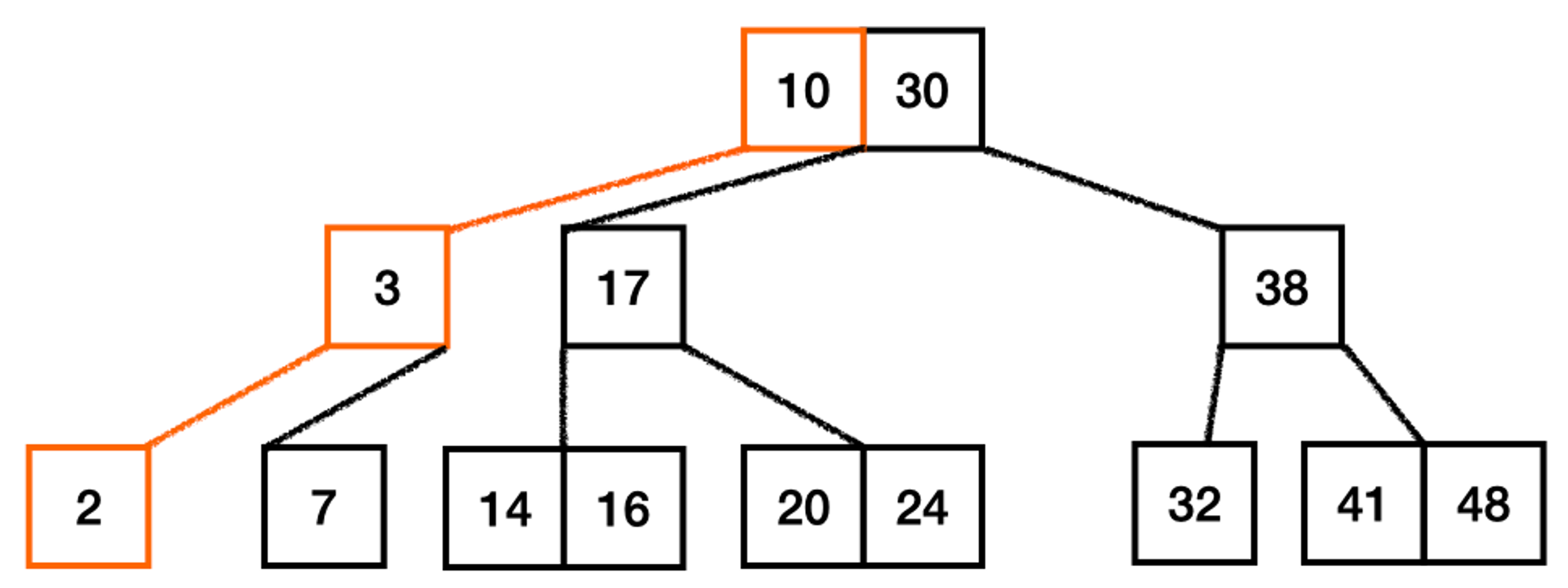
데이터의 정렬에도 도움이 된다니, 인덱스는 참 여러모로 유용한 기능이지요. B-Tree 알고리즘이 트리에 키를 정렬된 상태로 저장하기 때문입니다. 아래에 예시로 B-Tree를 첨부했습니다. 왼쪽 가지에 연결된 자식 노드의 값보다 키의 값이 크고, 오른쪽 가지에 연결된 자식 노드의 값보다는 키가 작지요. 각 노드에 여러 키가 들어가는 경우에도 키가 정렬되어 있고요. B+Tree는 잎 노드에 모든 키가 다 들어있기 때문에 좀 더 정렬된 값을 쉽게 파악할 수 있습니다.
정렬은 다른 타입의 인덱스에는 해당하지 않는 기능입니다. 예를 들어, Hash 알고리즘만 보더라도 데이터를 정렬에는 도움이 안됩니다. 심지어 Hash 인덱스는 = 이외의 다른 연산자(>, < 등)를 지원하지도 않죠. B-Tree 인덱스가 가장 범용적으로 사용되는데에는 다 이유가 있는 것 같습니다.
이 번역 작업이 여러분이 인덱스에 대해 공부하는데 도움이 되었으면 좋겠습니다. PostgreSQL 공식 문서가 인덱스에 대해 잘 쓰여져 있어 이전부터 번역을 꼭 해오고 싶었는데요. 흔쾌히 허가해주신 PostgreSQL CoC(Code of Conduct)팀 감사합니다. 이해를 돕기 위해 역자의 의역이 섞여있으니 만약 번역과 원문 간에 차이가 있는 경우 원문을 우선적으로 생각해주세요. 번역 오류는 contact@datarian.io로 제보해주세요.

 PostgreSQL
PostgreSQL